As I continue exploring the world of artificial intelligence, one issue keeps coming up: AI models making up answers when they don’t know something. It’s one of the biggest frustrations for AI developers and users alike—how can we trust AI if it’s guessing or fabricating information?
This is where Retrieval-Augmented Generation (RAG) comes in, and I’m diving deep into understanding how it works and whether it’s the key to building AI that’s fact-based, reliable, and useful.
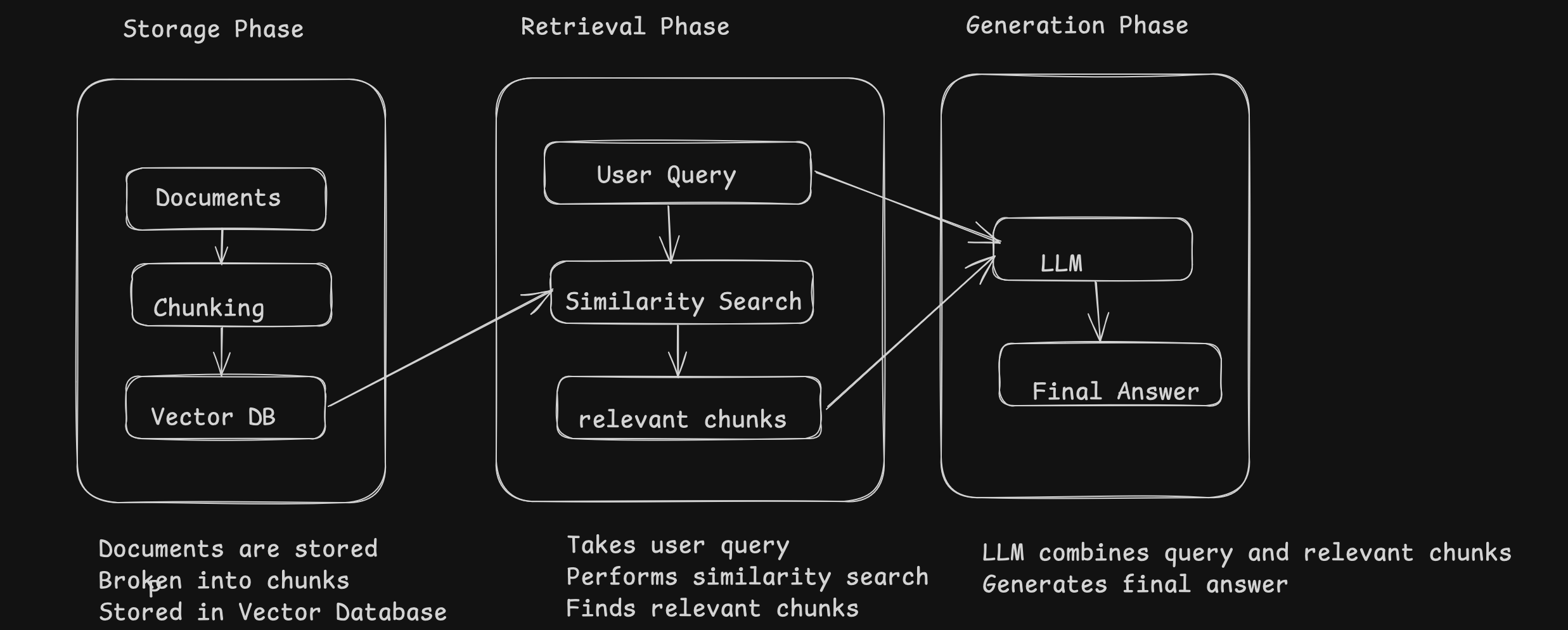
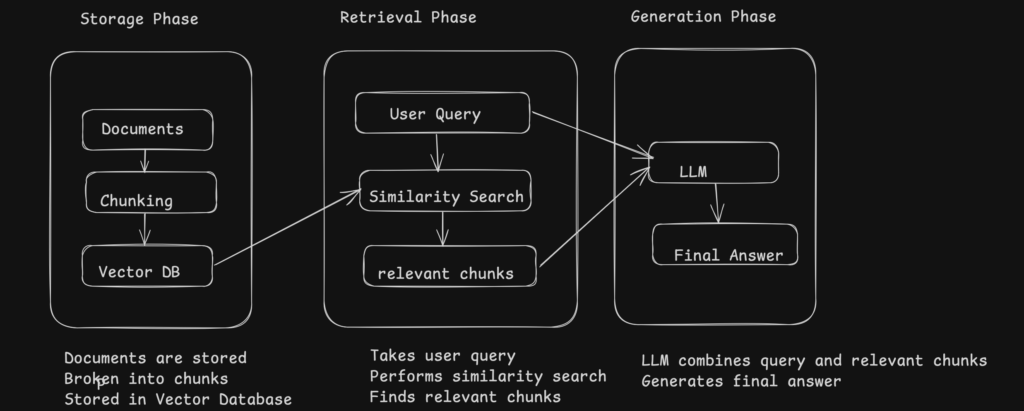
What Is RAG?
At its core, Retrieval-Augmented Generation (RAG) is a hybrid approach that combines two powerful aspects of AI:
- Retrieval models: These are systems designed to find and retrieve relevant information from large datasets or external sources.
- Generative models: These are AI systems (like GPT-4) that create meaningful responses based on inputs they receive.
In traditional AI systems, the model’s knowledge is static—once it’s trained on a dataset, it can’t update or retrieve new data unless retrained. This limitation can lead to hallucinations, where the AI “makes up” facts or provides outdated responses. But with RAG, the model can pull in real-time information from external sources, which makes its responses far more accurate.
How RAG Works: Key Insights
As I’ve been diving into how RAG actually works, I’ve learned a few key concepts that show why it could make AI much more reliable:
- AI Can Retrieve Real Data Before Generating a Response
Unlike traditional models, RAG-powered systems don’t just rely on the information they were trained on. They can fetch relevant data from external sources, whether it’s from a knowledge base, live database, or documents, before generating a response. This ability to ground the model’s responses in factual, up-to-date information is a game-changer for building reliable AI systems. - Indexing Matters a Lot
To make sure the system retrieves the right information, the data needs to be properly organized and indexed. This involves turning documents into vector embeddings, essentially mathematical representations that make it easier for the system to search and retrieve the most relevant information quickly and accurately. The smarter the indexing, the better the retrieval. - The Retrieval Strategy You Choose Makes All the Difference
There are different methods for retrieving information, and the approach you use can drastically affect the system’s effectiveness:- Dense Retrieval: This method uses vector similarity, meaning it searches for information based on the meaning behind the words rather than just matching keywords.
- Sparse Retrieval: Classic keyword-based search, matching words or phrases in the query to the text in the database.
- Hybrid Retrieval: A combination of both dense and sparse retrieval methods to improve the accuracy and relevance of the results.
- Semantic Search: This approach goes beyond exact matches and tries to understand the underlying meaning or context of the query to find more relevant answers.
Why Does This Matter?
The potential of RAG to make AI more reliable is huge. Here are a few reasons why:
- More Accurate, Real-Time Responses: By retrieving relevant, factual data and using it to generate responses, RAG ensures that AI isn’t just “making things up.” Instead, it provides answers grounded in real-time, relevant data sources.
- AI Applications That Can Stay Up-to-Date: With RAG, AI models can pull in fresh data as needed, ensuring that they don’t just rely on outdated knowledge.
- Improved User Trust: AI systems powered by RAG can become more trustworthy by delivering factual and accurate responses, which is crucial for applications like chatbots, customer service tools, and AI-powered search engines.
My Next Steps: Building With RAG
As I continue exploring RAG, I’m also planning to build my own AI application that uses this approach to provide real-time, reliable responses. By leveraging RAG, I aim to create a system that goes beyond guessing and provides factual answers, no matter the query.
But there’s still a lot I need to understand. RAG systems aren’t simple to implement, and challenges like data retrieval speed, accuracy, and ensuring reliable sources will be crucial as I start building.
What’s Next?
I’m still in the early stages of learning and experimenting with RAG, but I’m excited to see where this approach can take AI. If you’ve worked with RAG or have experience with AI systems that integrate real-time data retrieval, I’d love to hear your thoughts and advice.
What challenges have you faced when trying to implement RAG? What’s the biggest impact you’ve seen from using this technology?
Let’s continue the conversation and learn together.
Conclusion
RAG is an exciting step forward in making AI more reliable and useful. With the ability to retrieve real-time information and generate data-driven responses, it has the potential to reshape the way we build and interact with AI applications. I’m excited to continue this journey and explore how I can implement RAG in my own projects.
#AI #MachineLearning #RAG #TechInnovation #AIApplications
![]()